Python scripts
Python scripts empower businesses and individuals to optimize workflows, automating repetitive tasks and complex data manipulation, thereby significantly improving productivity and freeing up valuable time for more creative and strategic pursuits.
Create_structure
Description
Importing tracker data into spreadsheet, these are then auto-filtered into a separate tab. Script reads the filtered spreadsheet, gathers data and looks for matching _DOC, _UI and Analysis files. If file names match the project name, file and folder structure is created based on predefined rules.
Estimated time saved: 30 minutes daily
Animation
Code Sample
import openpyxl
import os
import shutil
import zipfile
"""GLOBAL VARIABLES"""
main_dir = "c:\\Users\\PioGr\\Downloads\\AutoMate\\"
toWOL = "AutoMate.xlsx"
WOLfolder = "02_toWOL"
source_dir = "00_source"
analysis_dir = "Analysis"
xliff = "__XLIFF"
documentation = "__DOC"
interface = "__UI"
structure = "_structure_toWOL"
filepath = os.path.join(main_dir, toWOL)
workbook = openpyxl.load_workbook(filepath, data_only=True)
sheet = workbook["to_WOL"]
# Store project data in a dictionary
project_data = {}
def main():
gather_project_data()
create_structure()
def gather_project_data():
"""Get project data from XLSX file"""
# Iterate through the rows, starting from second row
for row in sheet.iter_rows(min_row=2):
# Indexing into a row to extract values
product = row[0].value
type = row[1].value
project_name = row[2].value
language = row[3].value
deadline = row[4].value
project_code = row[5].value
# Store data in a more structured way
if project_name not in project_data:
project_data[project_name] = {
'product': product,
'type': type,
'deadline': deadline,
'languages': [],
'project_code': project_code
}
project_data[project_name]['languages'].append(language)
def create_structure():
"""Create full file and folder structure"""
# Change extension to XLZ for all source files
extension_XLZ()
# Iterate through unique project names
for project_name, data in project_data.items():
# Truncate the project name
parts = project_name.split('_', 1)
if len(parts) >= 2:
truncated_name = parts[1]
else:
truncated_name = project_name
# Folder creation
project_folder_path = os.path.join(main_dir, project_name)
# Full structure processing, each function described with its DOCSTRING
folder_creation(project_name, project_folder_path)
copy_WOL_structure(project_folder_path)
analysis_file_copy(project_name, truncated_name)
copy_XLIFF(project_name, truncated_name)
zip_creation(project_name, project_folder_path)
def extension_XLZ():
"""Changing files extensions in XLIFF folder to XLZ"""
source_path = os.path.join(main_dir, xliff)
try:
for filename in os.listdir(source_path):
src_file = os.path.join(source_path, filename)
if os.path.isfile(src_file):
base, ext = os.path.splitext(src_file)
new_file = f"{base}.xlz"
os.rename(src_file, new_file)
print("Source file extensions changed to .xlz!")
except Exception as e:
print(f"Error occurred: {e}")
def folder_creation(project_name, project_folder_path):
"""Folder creation"""
if not os.path.exists(project_folder_path): # Check if the folder exists
try:
os.mkdir(project_folder_path)
except OSError:
print(f"Creation of the directory {project_folder_path} failed")
else:
print(f"Successfully created the directory {project_name}")
else:
print(f"Directory {project_folder_path} already exists. Skipping.")
def copy_WOL_structure(project_folder_path):
"""Copy folder structure from WOL directory"""
# Copy structure_toWOL contents
source_folder = os.path.join(main_dir, structure) # Path to '_structure_toWOL'
for file_or_dir in os.listdir(source_folder):
src = os.path.join(source_folder, file_or_dir)
dest = os.path.join(project_folder_path, file_or_dir)
if not os.path.exists(dest): # Check if the destination exists
try:
if os.path.isdir(src): # If it's a directory
shutil.copytree(src, dest)
else: # If it's a file
shutil.copyfile(src, dest)
except shutil.Error as e:
print(f"Error copying from {src} to {dest}: {e}")
else:
print(f"{dest} already exists. Skipping.")
def analysis_file_copy(project_name, truncated_name):
"""Copy analysis files from UI and DOC folders to structure"""
for type in ["DOC", "UI"]:
if type == "DOC":
source_path = os.path.join(main_dir, documentation)
elif type == "UI":
source_path = os.path.join(main_dir, interface)
target_path = os.path.join(main_dir, project_name, analysis_dir)
os.makedirs(target_path, exist_ok=True) # Create target directory
for filename in os.listdir(source_path):
if truncated_name in filename:
source_file = os.path.join(source_path, filename)
target_file = os.path.join(target_path, filename)
shutil.copy2(source_file, target_file)
#print(filename)
def copy_XLIFF(project_name, truncated_name):
"""Copy XLIFF files from XLIFF folder intro structure"""
# Copy WSXZ / XLIFF files
source_path = os.path.join(main_dir, xliff)
target_path = os.path.join(main_dir, project_name, source_dir)
os.makedirs(target_path, exist_ok=True)
for filename in os.listdir(source_path):
# Change required for XLF files, as they have random blank spaces instead of "_"
try:
filename_no_spaces = filename.replace(" ", "_") # Replace spaces with underscores
os.rename(os.path.join(source_path, filename), os.path.join(source_path, filename_no_spaces))
#print("Renamed:", filename, "->", filename_no_spaces)
filename = filename_no_spaces # Update the filename variable for consistency
except OSError as e:
print("Error renaming file:", e)
if truncated_name in filename:
source_file = os.path.join(source_path, filename)
target_file = os.path.join(target_path, filename)
shutil.copy2(source_file, target_file)
def zip_creation(project_name, project_folder_path):
"""Create zip files within the structure"""
# Create project-specific ZIP destination
project_folder_path = os.path.join(main_dir, project_name)
zip_dest = os.path.join(project_folder_path, WOLfolder)
os.makedirs(zip_dest, exist_ok=True)
# Zip "00_source" files
source_path = os.path.join(project_folder_path, source_dir)
if os.path.exists(source_path): # Check if the source folder exists
os.chdir(source_path)
with zipfile.ZipFile(os.path.join(zip_dest, 'source.zip'), 'w', zipfile.ZIP_DEFLATED) as zip_file:
for file in os.listdir():
zip_file.write(file)
else:
print(f"Warning: Source folder not found for project: {project_name}")
# Zip "Analysis" files
analysis_path = os.path.join(project_folder_path, analysis_dir)
if os.path.exists(analysis_path):
os.chdir(analysis_path)
with zipfile.ZipFile(os.path.join(zip_dest, 'analysis.zip'), 'w', zipfile.ZIP_DEFLATED) as zip_file:
for file in os.listdir():
zip_file.write(file)
else:
print(f"Warning: Analysis folder not found for project: {project_name}")
if __name__ == "__main__":
main()CSV_download
Description
The script checks if the user's browser has a valid link where CSV analysis file may be downloaded. It then proceeds with "manual" download of the file and moves to the next tab, until all tabs have been processed. Also checks if PNG files are present in the handoff.
Estimated time saved: 45 minutes daily
Screenshot
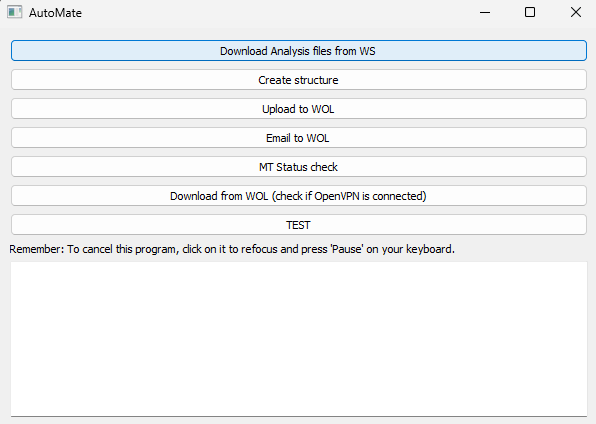
Disclaimer
Video animation unavailable.
Code Sample
import pygetwindow as gw
import pyautogui
import time
import re
import pyperclip
def main():
while analysis_window_check():
script_action()
def analysis_window_check():
"""
This function activates Chrome and checks the website address
"""
# Find all windows with title containing "Chrome"
chrome_windows = gw.getWindowsWithTitle(title="Chrome")
analysis_window = re.compile(r"https://ws.corp.adobe.com.+assignments_tasks.+")
# Check if any Chrome windows are found
if chrome_windows:
# Activate the first Chrome window
chrome_windows[0].activate()
# Get website address and check against regex
time.sleep(0.15)
pyautogui.hotkey('ctrl', 'l')
time.sleep(0.15)
pyautogui.hotkey('ctrl', 'c')
time.sleep(0.15)
pyautogui.hotkey('esc')
clipboard = pyperclip.paste()
if clipboard and re.match(analysis_window, clipboard):
return True
else:
return False
else:
return False
def script_action():
# ========= Main script action =========
# Simulate Ctrl+F
pyautogui.hotkey('ctrl', 'f')
# Type your search text
pyautogui.typewrite("View scoping information")
time.sleep(0.5)
# Simulate Enter to execute the search or select the found link
pyautogui.press('enter')
time.sleep(0.5)
# Simulate escape
pyautogui.press('escape')
time.sleep(0.5)
# Simulate menu key
pyautogui.hotkey('shift', 'f10')
time.sleep(0.5)
# Simulate arrow down
pyautogui.hotkey('down')
time.sleep(0.5)
# Simulate Enter
pyautogui.press('enter')
# Let the new page load
time.sleep(2)
# simulate ctrl+Tab
pyautogui.hotkey('ctrl', 'tab')
time.sleep(0.5)
# in scope window
# Simulate Ctrl+F
pyautogui.hotkey('ctrl', 'f')
# Type your search text
pyautogui.typewrite("Download as CSV file")
time.sleep(0.5)
# Simulate Enter to execute the search or select the found link
pyautogui.press('enter')
time.sleep(0.5)
# Simulate Ctrl+Enter to download the file
pyautogui.hotkey('ctrl', 'enter')
time.sleep(2)
# simulate ctrl+w to close tab the Analysis tab
pyautogui.hotkey('ctrl', 'w')
time.sleep(0.5)
# Launch PNG handling function, leave PNG windows open, close otherwise
if PNG_check():
pyautogui.hotkey('ctrl', 'tab')
time.sleep(0.5)
else:
pyautogui.hotkey('ctrl', 'w')
time.sleep(0.5)
def PNG_check():
# ========= PNG Search Logic =========
time.sleep(0.25)
pyautogui.hotkey('ctrl', 'a')
pyautogui.hotkey('ctrl', 'c')
time.sleep(0.25)
clipboard_text = pyperclip.paste() # Read from the system clipboard
if "png" in clipboard_text.lower():
print("PNGs found.")
return True
else:
return False
if __name__ == "__main__":
main()Bug_report_cleanup
Description
This script aims to clean up the data in a spreadsheet that contains several hundred software bug reports. As the data was inconsistent, there are numerous steps required to ensure clean, consistent output.
Estimated time saved: 16 hours, one-off
Disclaimer
Video animation unavailable as it contains sensitive information.
Code Sample
import re
from openpyxl import load_workbook, Workbook
import openpyxl
def main():
filter1()
add_lines()
remove_comments()
remove_empty_lines()
layout_change()
layout_change2()
layout_change3()
remove_lines()
def add_lines():
file_path = "c:\\Users\\PioGr\\Downloads\\_bugs\\WF_analysis_filtered"
# Load the workbook
workbook = openpyxl.load_workbook(filename=f"{file_path}.xlsx")
# Assuming data is in sheet1
sheet1 = workbook["Sheet"]
# Define the regular expression patterns to search for
pattern1 = r'\[LING.+\]'
pattern2 = r'Category:'
pattern3 = r'Expected Category:'
pattern4 = r'Comments:'
max_rows = sheet1.max_row # Get the maximum number of rows in the sheet
# Read initial lines
current_row = 1 # Keep track of the current row
while current_row <= max_rows:
line1 = sheet1.cell(row=current_row, column=1).value
line2 = sheet1.cell(row=current_row + 1, column=1).value if current_row + 1 <= max_rows else None
line3 = sheet1.cell(row=current_row + 2, column=1).value if current_row + 2 <= max_rows else None
line4 = sheet1.cell(row=current_row + 3, column=1).value if current_row + 3 <= max_rows else None
# Check for matching patterns in the group of four lines
if re.search(pattern1, line1):
if line2 is None or not re.search(pattern2, line2):
sheet1.insert_rows(current_row + 1)
sheet1.cell(row=current_row + 1, column=1).value = "Category:"
if line3 is None or not re.search(pattern3, line3):
sheet1.insert_rows(current_row + 2)
sheet1.cell(row=current_row + 2, column=1).value = "Expected Category:"
if line4 is None or not re.search(pattern4, line4):
sheet1.insert_rows(current_row + 3)
sheet1.cell(row=current_row + 3, column=1).value = "Comments:"
print(f"Lines {current_row} to {current_row + 3} match the expected patterns.")
else:
# Pattern 1 doesn't match, so we don't need to check the others
current_row += 1
continue
workbook.save(f"{file_path}_2.xlsx") # Save the changes to the Excel file
current_row += 4 # Move to the next group of four lines
def remove_lines():
# Replace with the actual path to your file (without extension)
file_path = "c:\\Users\\PioGr\\Downloads\\_bugs\\WF_analysis_6"
# Read the data from sheet1
workbook = load_workbook(filename=f"{file_path}.xlsx") # Provide the filename
sheet1 = workbook["Sheet"] # Assuming data is in sheet1
# Create a new workbook for writing the filtered data
output_workbook = Workbook()
output_sheet = output_workbook.active
pattern1 = r'\[LING.+\]'
import re
row_num = 1
for row in sheet1.iter_rows(min_row=1, max_col=sheet1.max_column, values_only=True):
row_data = ''.join(str(cell) for cell in row)
if re.search(pattern1, row_data):
output_sheet.append(row)
row_num += 1
# Save the output workbook
output_workbook.save(f"{file_path}_7.xlsx")
def layout_change3():
# Replace with the actual path to your file (without extension)
file_path = "c:\\Users\\PioGr\\Downloads\\_bugs\\WF_analysis_5"
# Read the data from sheet1
workbook = load_workbook(filename=f"{file_path}.xlsx") # Provide the filename
sheet1 = workbook["Sheet"] # Assuming data is in sheet1
# Create a new workbook for writing the filtered data
output_workbook = Workbook()
output_sheet = output_workbook.active
# Copy all cells from the input sheet to the output sheet
for row_num in range(1, sheet1.max_row + 1):
for col_num in range(1, sheet1.max_column + 1):
cell_value = sheet1.cell(row=row_num, column=col_num).value
output_sheet.cell(row=row_num, column=col_num, value=cell_value)
# Move cells B4, B8, B12, etc. to D1, D5, D9, etc.
row_index = 1
target_row_index = 1
for row_num in range(4, sheet1.max_row + 1, 4):
cell_value = sheet1.cell(row=row_num, column=2).value
output_sheet.cell(row=target_row_index, column=4, value=cell_value)
row_index += 1
target_row_index += 4
# Save the output workbook
output_workbook.save(f"{file_path}_6.xlsx")
def layout_change2():
# Replace with the actual path to your file (without extension)
file_path = "c:\\Users\\PioGr\\Downloads\\_bugs\\WF_analysis_4"
# Read the data from sheet1
workbook = load_workbook(filename=f"{file_path}.xlsx") # Provide the filename
sheet1 = workbook["Sheet"] # Assuming data is in sheet1
# Create a new workbook for writing the filtered data
output_workbook = Workbook()
output_sheet = output_workbook.active
# Copy all cells from the input sheet to the output sheet
for row_num in range(1, sheet1.max_row + 1):
for col_num in range(1, sheet1.max_column + 1):
cell_value = sheet1.cell(row=row_num, column=col_num).value
output_sheet.cell(row=row_num, column=col_num, value=cell_value)
# Move cells B3, B7, B11, etc. to C1, C5, C9, etc.
row_index = 1
target_row_index = 1
for row_num in range(3, sheet1.max_row + 1, 4):
cell_value = sheet1.cell(row=row_num, column=2).value
output_sheet.cell(row=target_row_index, column=3, value=cell_value)
row_index += 1
target_row_index += 4
# Save the output workbook
output_workbook.save(f"{file_path}_5.xlsx")
def layout_change():
# Replace with the actual path to your file (without extension)
file_path = "c:\\Users\\PioGr\\Downloads\\_bugs\\WF_analysis_3"
# Read the data from sheet1
workbook = load_workbook(filename=f"{file_path}.xlsx") # Provide the filename
sheet1 = workbook["Sheet"] # Assuming data is in sheet1
# Create a new workbook for writing the filtered data
output_workbook = Workbook()
output_sheet = output_workbook.active
# Copy all cells from the input sheet to the output sheet
for row_num in range(1, sheet1.max_row + 1):
for col_num in range(1, sheet1.max_column + 1):
cell_value = sheet1.cell(row=row_num, column=col_num).value
output_sheet.cell(row=row_num, column=col_num, value=cell_value)
# Move cells B2, B6, B10, etc. to B1, B5, B9, etc.
for row_num in range(2, sheet1.max_row + 1, 4):
cell_value = sheet1.cell(row=row_num, column=2).value
output_sheet.cell(row=row_num - 1, column=2, value=cell_value)
# Save the output workbook
output_workbook.save(f"{file_path}_4.xlsx")
def remove_empty_lines():
# Replace with the actual path to your file (without extension)
file_path = "c:\\Users\\PioGr\\Downloads\\_bugs\\WF_analysis_filtered_filtered2"
# Read the data from sheet1
workbook = load_workbook(filename=f"{file_path}.xlsx") # Provide the filename
sheet1 = workbook["Sheet"] # Assuming data is in sheet1
# Create a new workbook for writing the filtered data
output_workbook = Workbook()
output_sheet = output_workbook.active
row_index = 1 # Start from row 1 (skipping the header row)
for row in sheet1.iter_rows(min_row=2): # Iterate over rows starting from row 2
if any(cell.value for cell in row): # Check if at least one cell in the row has a value
for cell in row:
output_sheet.cell(row=row_index, column=cell.column, value=cell.value)
row_index += 1
# Save the output workbook
output_workbook.save(f"{file_path}_filtered3.xlsx")
def remove_comments():
# Replace with the actual path to your file (without extension)
file_path = "c:\\Users\\PioGr\\Downloads\\_bugs\\WF_analysis_filtered_2"
# Define the regular expression pattern to search for
pattern = r' Comments ' # Match "Comments"
# Read the data from sheet1
workbook = load_workbook(filename=f"{file_path}.xlsx") # Provide the filename
sheet1 = workbook["Sheet"] # Assuming data is in sheet1
# Create a new workbook for writing the filtered data
output_workbook = Workbook()
output_sheet = output_workbook.active
# Iterate over rows in sheet1
for row_num, row in enumerate(sheet1.iter_rows(values_only=True), start=1):
# Check if the regular expression pattern matches any cell in the current row
if not any(re.search(pattern, str(cell).strip()) for cell in row):
# Write the row to the output sheet if it doesn't contain "Comments"
output_sheet.append(row)
# Save the output workbook
output_workbook.save(f"{file_path}_filtered2.xlsx")
def filter1():
# Replace with the actual path to your file (without extension)
file_path = "c:\\Users\\PioGr\\Downloads\\_bugs\\WF_analysis"
# Define the regular expression pattern to search for
pattern = r'\[LING.+\]|Category|Comments:' # Match "[LING......]" or "Category"
# Read the data from sheet1
workbook = load_workbook(filename=f"{file_path}.xlsx") # Provide the filename
sheet1 = workbook["Sheet1"] # Assuming data is in sheet1
# Create a new workbook for writing the filtered data
output_workbook = Workbook()
output_sheet = output_workbook.active
# Iterate over rows in sheet1
for row_num, row in enumerate(sheet1.iter_rows(values_only=True), start=1):
# Check if the regular expression pattern matches any cell in the current row
if any(re.search(pattern, str(cell).strip()) for cell in row):
# Write the row to the output sheet
output_sheet.append(row)
# Save the output workbook
output_workbook.save(f"{file_path}_filtered.xlsx")
if __name__ == "__main__":
main()